

Tworzenie oraz rozbudowa treści na stronie internetowej to jedno z kluczowych działań wspierających efektywną strategię SEO. Jednak poza dbałością o dostarczanie botom wyszukiwarki oraz użytkownikom nowej porcji contentu nie zapominajmy o zasobach, które już znajdują się na naszej witrynie. Nierzadko okazuje się, że problem z budowaniem widoczności organicznej, przekładającej się na poziom konwersji prowadzonego biznesu, drzemie właśnie w nieodpowiednio zarządzanych treściach: niskiej jakości, nieaktualnych bądź właśnie nieunikalnych.
Upewnij się, czy twoja strona lub sklep internetowy zmagają się z problemem duplikacji treści, a także poznaj sposoby, zgodne z aktualnymi wytycznymi wyszukiwarki Google, na skuteczne zarządzanie duplicate content w SEO.
Co to jest duplikacja treści?
Duplikacja treści, znana także (zwłaszcza w anglojęzycznych źródłach) pod określeniem “duplicate content”, to każda treść, która pojawia się na więcej niż jednej podstronie jednej bądź wielu domen.
Warto zaznaczyć, że zduplikowana treść bywa identyczna, ale równie dobrze może łudząco przypominać inną, a więc np. zostać utworzona według mocno zbliżonego schematu bądź być poddana jedynie pobieżnemu przeredagowaniu. Pomimo iż problem z duplicate content w SEO nie zawsze musi oznaczać celową kradzież materiałów, nawet nieświadome kopiowanie treści oraz wewnętrzne zaniedbania na stronie w tym zakresie mogą niekorzystnie wpłynąć na wyniki domeny związane z generowaniem ruchu organicznego w wyszukiwarce.
Duplikacja treści a Google – wytyczne
Najważniejsze pytanie brzmi: czy duplicate content szkodzi SEO?
Odpowiedź zapewne nikogo nie zaskoczy: to zależy.
Na pewno możemy uznać, iż celowe powielanie treści pozostaje w sprzeczności z wytycznymi Google dotyczącymi unikalności treści, a co za tym idzie, także z najlepszymi praktykami w strategii pozycjonowania domeny. Nie należy jednak obawiać się nałożenia kary algorytmicznej bądź manualnej za ten “występek” – o ile wyraźnie nie przekraczamy granic wytyczonych przez twórców wyszukiwarki.
John Mueller w jednej z wypowiedzi w 2021 roku jednoznacznie zaprzeczył, iż problem duplicate content bezpośrednio przekłada się na niższą ocenę witryny przez algorytm wyszukiwarki. Zwrócił natomiast uwagę na aspekt wyboru przez algorytm i wyświetlania w wynikach wyszukiwania podstrony jednej domeny spośród kilku zawierających powieloną treść – tej podstron, która najlepiej pasuje do wpisywanego zapytania.
Przy ustalaniu, którą domenę najlepiej wyświetlić użytkownikom wyszukiwarki, pod uwagę mogą zostać wzięte pod uwagę takie aspekty jak:
- pierwszeństwo “zauważenia” (indeksacji) przez Google’a,
- autorytet domeny (w tym liczba domen odsyłających, profil linków i historia domeny),
- dopasowanie tematyczne do frazy kluczowej i intencji wyszukiwania.
Pozostałe podstrony z duplikowanymi treściami mogą zostać pominięte przez systemy deduplikacji Google’a.
Co to oznacza dla naszej strony?
Występowanie duplikatów – zarówno wewnętrznych, jak i zewnętrznych – może okazać się przyczyną utrudnień w osiąganiu wysokich pozycji w wynikach wyszukiwania. To z kolei wiąże się z dużo niższym poziomem ruchu organicznego. Ponadto występowanie treści powielonej w obrębie kilku domen może zniechęcać użytkowników do kontynuowania sesji w witrynie, przyczyniając się do zwiększania współczynnika odrzuceń (bounce rate) dla danej podstrony.
Twórcy wyszukiwarki Google (np. Matt Cutts w materiale wideo na kanale Google Search Central z 2013 roku) uspokajają, iż algorytm jest gotowy na przypadki duplicate content, które mogą się zdarzyć i nie zostaną uznane za spam bądź próbę manipulacji (np. stopka występująca w niezmienionej postaci na każdej podstronie serwisu, cytaty artykułów zewnętrznych bądź opisy produktowe na różnych platformach e-commerce). Co więcej, za naturalne jest uznawane występowanie nieznacznego udziału powielonych zasobów w witrynie (ok. 25-30%).
Naturalność i umiar – to one stanowią podstawowy wyznacznik oceny, czy problem duplicate content dotyczy naszej domeny.
Szukając wskazówek, którymi należy kierować się w ocenie jakości treści na stronie internetowej, warto na bieżąco śledzić wytyczne twórców wyszukiwarki. Dobrym wyznacznikiem będzie również przebieg wdrożeń update’ów algorytmu, nieustannie poddawanego usprawnieniom pod kątem metod weryfikacji i interpretacji treści w taki sposób, by oferować użytkownikom wysoce jakościowe, wiarygodne i użyteczne materiały.
Dla przypomnienia: już w 2011 roku światło dzienne ujrzał update algorytmu o nazwie Panda, zorientowany na poprawę jakości treści wyświetlanych w organicznych wynikach wyszukiwania. Weryfikacja podstron przez algorytm Google pod kątem zamieszczanych treści miała na celu skupiać się na ograniczeniu widoczności zasobom niskiej jakości: powielonym, niosącym znikomą wartość dla użytkowników.
Priorytetyzacja jakościowych treści przez algorytm przejawia się także w takich zmianach jak wprowadzone w 2022 roku: koncepcja E-E-A-T (ang. Expertise-Experience-Authoritativeness-Trust) oraz Helpful Content Update. Wyszukiwarka Google z każdym rokiem coraz mocniej dąży do wyświetlania na najwyższych pozycjach wyników wyszukiwania swoim użytkownikom najlepiej dopasowanych, adekwatnych, przydatnych i wiarygodnych domen.
Rodzaje duplicate content w SEO
Zmagania z duplikatami treści nie należą do najłatwiejszych – przede wszystkim z uwagi na mnogość przypadków, w których zawartość podstron zostaje powielona.
Zacznijmy zatem od podstawowego podziału: duplicate content może występować zarówno wewnętrznie, na podstronach tej samej domeny, jak i zewnętrznie, gdy kopie tekstów znajdują się na podstronach więcej niż jednej domeny.
Wewnętrzna duplikacja treści
Wewnętrzna duplikacja treści dzieje się w obrębie jednej domeny. Mówiąc bardziej obrazowo, ten typ duplikatów to przede wszystkim powielone fragmenty treści na różnych podstronach tej samej witryny bądź duplikaty podstron na różnych adresach URL, ale identycznej (lub mocno zbliżonej) treści.
W jaki sposób wewnętrzny duplicate content szkodzi witrynie?
Z punktu widzenia SEO duplikacja treści wiąże się przede wszystkim ze zwiększonym ryzykiem kanibalizacji podstron na te same słowa kluczowe. Budowanie widoczności podstrony na określone frazy kluczowe może okazać się szczególnie problematyczne, gdy okaże się, że w ramach naszej domeny funkcjonuje nie jedna, a dwie bądź więcej podstron o takiej samej (lub istotnie zbliżonej) zawartości. Podstrony zaczynają wtedy często “walczyć” ze sobą o jak najlepsze miejsce w wynikach wyszukiwania, w efekcie czego żadna z nich nie osiąga topowych pozycji. Zamiast tego warto skupić się na konkurencji z zewnętrznymi domenami z pomocą podstrony o unikalnych, wartościowych treściach.
Duplicate content odnoszący się do całych podstron serwisu to często efekt niepomyślnie wdrożonych zmian technicznych. Przykładowo, gdy domena obsługuje zarówno adresy URL z “www” oraz bez tego przedrostka (ten sam przypadek z “https:// i “http://” oraz wersje adresów URL z “/” na końcu i bez niego), a nie zostały wdrożone przekierowania 301 na właściwą wersję adresu URL, możemy spodziewać się znaczącej liczby zduplikowanych podstron. Taki obrót spraw nie tylko uniemożliwi osiąganie znaczących pozycji w organicznych wynikach wyszukiwania, lecz także, gdy problem domeny ma zasięg globalny, może znacząco ograniczyć jej budżet crawlowania, utrudniając pracę botom skanującym i indeksującym zawartość.
Ponadto wewnętrzna duplikacja treści może dotknąć witrynę, która obsługuje odmienne wersje adresów URL dla użytkowników urządzeń mobilnych i stacjonarnych (np. w wersji mobile występują adresy z m.domena.pl). Równie istotna niekiedy okazuje się weryfikacja tzw. śledzących adresów URL (z tagami UTM). Warto sprawdzić poprawność wdrożenia mechanizmów tworzenia takich adresów URL.
Zewnętrzna duplikacja treści
Zewnętrzna duplikacja to rodzaj duplicate content, który dotyczy więcej niż jednej domeny – powielona treść występuje na co najmniej dwóch domenach, a niekiedy krąży w niezmienionej postaci w wielu różnych miejscach w sieci.
Rozważając formy występowania zewnętrznych duplikatów, na myśl najszybciej nasuwa się niechlubna praktyka plagiatu tekstów – gdy treść została pozyskana z domeny bez zgody jej właściciela i udostępniona w innym serwisie. Warto w tym miejscu przypomnieć, iż jest to kradzież własności intelektualnej. Budowanie bazy treści na stronie zgodnie z taką strategią może przynieść efekty odwrotne do zamierzonych: zarówno z punktu widzenia pozycjonowania, jak i wizerunku marki.
Bez obaw, nie każdy przejaw zewnętrznej duplikacji treści oznacza plagiat. Istnieją (wbrew pozorom bardzo częste) przypadki, w których powielanie treści jest powszechnie stosowaną praktyką. Zaliczamy do nich np. powielane opisy produktowe w kilku sklepach internetowych oraz na różnych platformach sprzedażowych. Wielokrotna publikacja notki prasowej w kilku serwisach informacyjnych (bądź publikacji sponsorowanej na więcej niż jednym portalu) to także przykład zewnętrznego duplicate content.
Przykłady duplicate content w sklepie internetowym
- Listing z produktami: indeksowane podstrony paginacji / filtrowania / sortowania – gdy decydujemy się na dopuszczenie do indeksacji kolejnych podstron paginacji, warto usunąć z tych podstron opis kategorii, aby treść nie została uznana za duplicate content. Podobne działanie sprawdzi się w przypadku podstron generowanych w ramach filtrowania i/lub sortowania listy produktów (jeżeli generują one nowe adresy URL z parametrem).
- Podstrona produktowa: opisy produktowe – godną pochwały praktyką jest opracowywanie unikalnych opisów produktowych zamiast zaciągania tekstów udostępnianych przez producenta. W przypadku ograniczonych zasobów w pierwszej kolejności można skupić się na topowych produktach, priorytetowych z punktu widzenia prowadzonego biznesu bądź budzących największe zainteresowanie wśród użytkowników wyszukiwarki. Dzięki opracowaniu rozbudowanych, zoptymalizowanych pod SEO treści produktowych zyskujemy szansę na zwiększenie użyteczności opracowanego opisu, co wesprze budowanie pozytywnych doświadczeń użytkowników. Co więcej, wyróżnimy się na tle konkurencji, prezentującej na analogicznej podstronie produktu ogólny, wielokrotnie powielany opis.
- Podstrona produktowa: różne warianty produktów (o różnym kolorze / wielkości) – oferując w sklepie jeden typ produktu o różnych parametrach (np. ten sam model plecaka w odmiennych wzorach) należy zwrócić uwagę na to, by oferta każdego z wariantów została zawarta na jednej, zbiorczej podstronie. Inna opcja to wdrożenie unikalnych opisów produktowych dla każdego z wariantów (gdy każdy z nich dysponuje osobną, indeksowaną podstronę, z unikalnym adresem URL).
Przykłady duplicate content na portalu contentowym
- Powielanie tekstów (nieprzemyślany “recykling treści”) – pomimo, iż sama idea recyklingu contentu jest godna uwagi, gdyż pozwala na wzmocnione wykorzystanie potencjału tworzonych treści, podejdźmy do tematu rozważnie. Na co należy uważać? Powtórna publikacja (pod nowym adresem URL) artykułu, który już widnieje w witrynie nie jest najlepszym pomysłem. Podobnie nie zaleca się praktyk “przepisywania” artykułów, zmieniając ich treść w nieznacznym stopniu – jeśli chcemy zaktualizować informacje zawarte w tekście, zróbmy to w trybie edycji już opublikowanego artykułu. Z kolei, jeżeli planowane jest połączenie kilku artykułów w jeden obszerniejszy, warto wdrożyć przekierowania 301 adresów URL (łączonych artykułów) na ten docelowy.
- Wpisy tworzone przez AI – choć kwestia wykorzystania technologii AI w SEO wzbudza wiele rozbieżnych opinii, nie pozostaje bez znaczenia także w kontekście duplicate content. Teksty tworzone przez AI bazują na zasobach, które już znajdują się w sieci, a zatem trudno mówić o nich jako o unikalnych, a tym bardziej wysoce jakościowych. Tym samym budowanie bazy contentowej serwisu w oparciu o artykuły, których autorem jest AI, w dłuższej perspektywie może okazać się co najmniej średnio efektywne, a czasem wręcz zgubne.
- Podstrony tagów – w rozbudowanych portalach contentowych sporym wyzwaniem z punktu widzenia SEO są podstrony tagów (odpowiedniki podkategorii), które w najgorszym przypadku tworzy się bez jakichkolwiek ograniczeń. Gdy w ramach każdego nowego artykułu powstanie kilka bądź kilkanaście kolejnych podstron tagów (często o mocno zbliżonych nazwach bądź kanibalizujących się z podstronami kategorii), zarządzanie nimi będzie stawać się coraz bardziej kłopotliwe. A stąd już prosta droga do problemu wewnętrznych duplikatów.
- Indeksowane podstrony paginacji – podobnie jak w przypadku domen e-commerce warto przyjrzeć się mechanizmowi generowania adresów URL kolejnych stron paginacji w widokach np. list artykułów lub sekcji komentarzy.
Przykłady duplicate content na stronie firmowej
- Opis “O firmie” – opis historii, misji i wizji firmy, a także jej podstawowej działalności to rodzaj treści, którą bardzo często wykorzystuje się zewnętrznie do realizacji działań PR marki. Tekst podstrony “O firmie” nie powinien być jednym i tym samym opisem co ten wykorzystywany każdorazowo na zewnętrznych domenach z profilami/wizytówkami firmy. Zamiast tego warto przygotować kilka unikalnych wariantów opisów, które będą wykorzystywane do różnych celów marketingowych.
- Różne wersje językowe witryny – problem może dotyczyć domen firm działających międzynarodowo, na więcej niż jednym rynku, a co za tym idzie, kierującym do swoich odbiorców ofertę w różnych wersjach językowych. Klucz do sukcesu leży w klarownym oznaczeniu analogicznych podstron za pomocą atrybutu hreflang, a także dokładnym (nieautomatycznym) tłumaczeniu treści z uwzględnieniem lokalnych fraz oraz uwarunkowań każdego z rynków.
Duplicate content a zdjęcia
W pierwszej kolejności duplikacja treści przywodzi na myśl kopiowanie fragmentów tekstu: artykułów, opisów, fragmentów tekstów. Czy zatem podobnie powinno się traktować grafiki i zdjęcia? Czy problem duplicate content dotyczy np. zdjęć produktowych, udostępnianych przez producenta i powielanych w obrębie wielu sklepów internetowych?
I tak, i nie.
Przede wszystkim algorytm Google jest w stanie rozpoznać identyczne bądź mocno zbliżone do siebie obrazy – przykład takiego działania algorytmu zauważamy, korzystając z funkcji wyszukiwania obrazem za pomocą Obiektywu Google. Do tego oficjalne wytyczne coraz częściej uwzględniają zapisy o wadze unikalności zasobów udostępnianych w ramach witryny.
Właśnie dlatego, gdy tylko możesz, stawiaj na unikalne grafiki. Taki krok zaprocentuje zarówno z perspektywy działań pozycjonowania zasobów domeny (podstron i obrazów) w wyszukiwarce, jak i zwiększania użyteczności treści dla użytkowników np. rozstrzygających problem decyzyjny zakupu produktu.
Co więcej, zadbaj o odpowiednią optymalizację grafik zgodnie z dobrymi praktykami SEO. Pamiętaj, by wprowadzić teksty alternatywne (tag “alt text”) dla każdego obrazu, a także zwróć uwagę na nazwę pliku – oba elementy powinny jednoznacznie wskazywać na zawartość pliku, być spójne z językiem strony, a przy tym wyrazy w nazwie pliku warto oddzielić myślnikami. Zgodnie z wytycznymi twórców wyszukiwarki rekomendowane formaty plików graficznych to: BMP, GIF, JPEG, PNG, WebP i SVG.
Udostępnianie bezpłatnych bądź wykupionych zdjęć z baz stockowych jest dopuszczalnym rozwiązaniem, które nie powinno zaszkodzić witrynie. Zdecydowanie zaleca się jednak unikać praktyk karalnych, wśród których, w kontekście powielania obrazów, prym wiedzie nielegalne wykorzystywanie grafik chronionych prawami autorskimi.
Jak sprawdzić duplicate content?
Stopień trudności weryfikacji duplicate content zależy m.in. od wielkości serwisu, poziomu złożoności struktury domeny, a także jej bazy contentowej. Warto poddać witrynę dokładnej analizie, korzystając z pomocy dostępnych narzędzi pozwalających na identyfikację duplikatów: wewnętrznych oraz zewnętrznych.
Narzędzia do sprawdzania duplicate content
Komenda “site:” (zewn./wewn. duplikacja treści)
Do weryfikacji treści na swojej oraz zewnętrznych domenach wystarczy sam Google. Wklejając tekst w okno wyszukiwarki, wyniki wyszukiwania wskażą, na jakich innych, zaindeksowanych domenach pojawia się identyczny (bądź mocno zbliżony) fragment. Można posiłkować się tutaj także komendą “site:” np. “site:domena.pl [fragment tekstu]”.

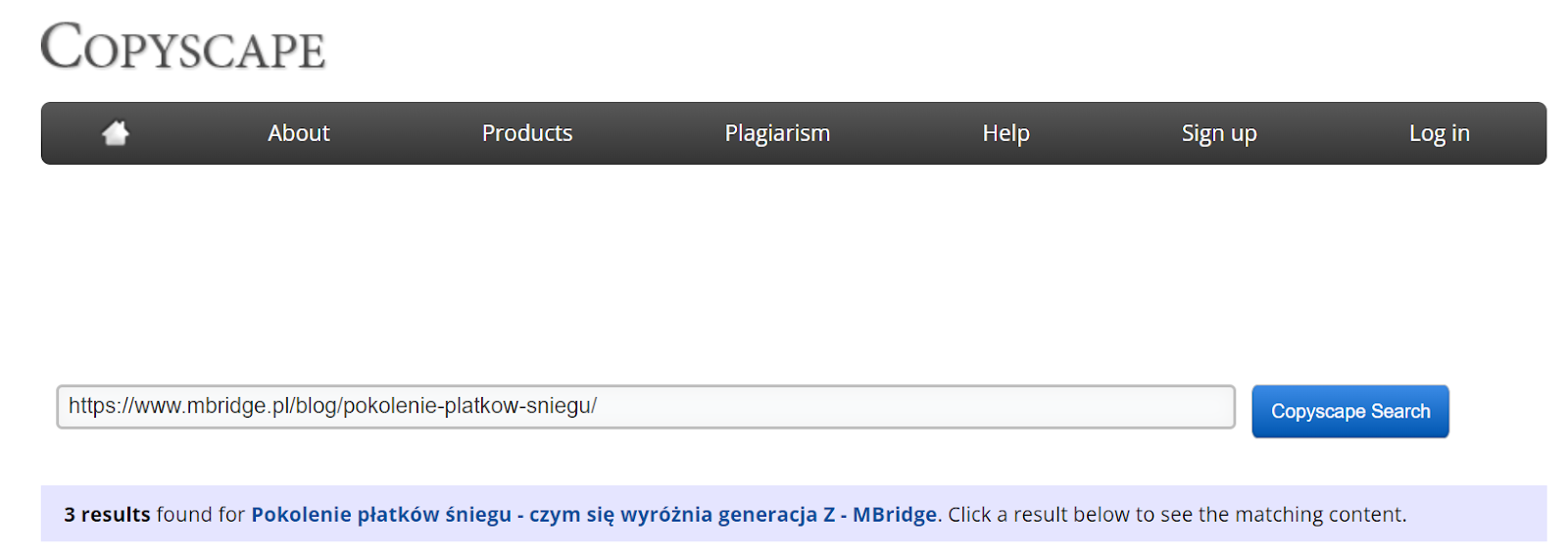
Copyscape (zewn. duplikacja treści)
To darmowe narzędzie online (w podstawowej wersji), pozwalające na szybkie sprawdzenie, czy treści z witryny powtarzają się na zewnętrznych domenach. Po wskazaniu adresu URL do sprawdzenia zostanie wyświetlona lista powielonych wycinków treści wraz z odnośnikami do źródła danego fragmentu.
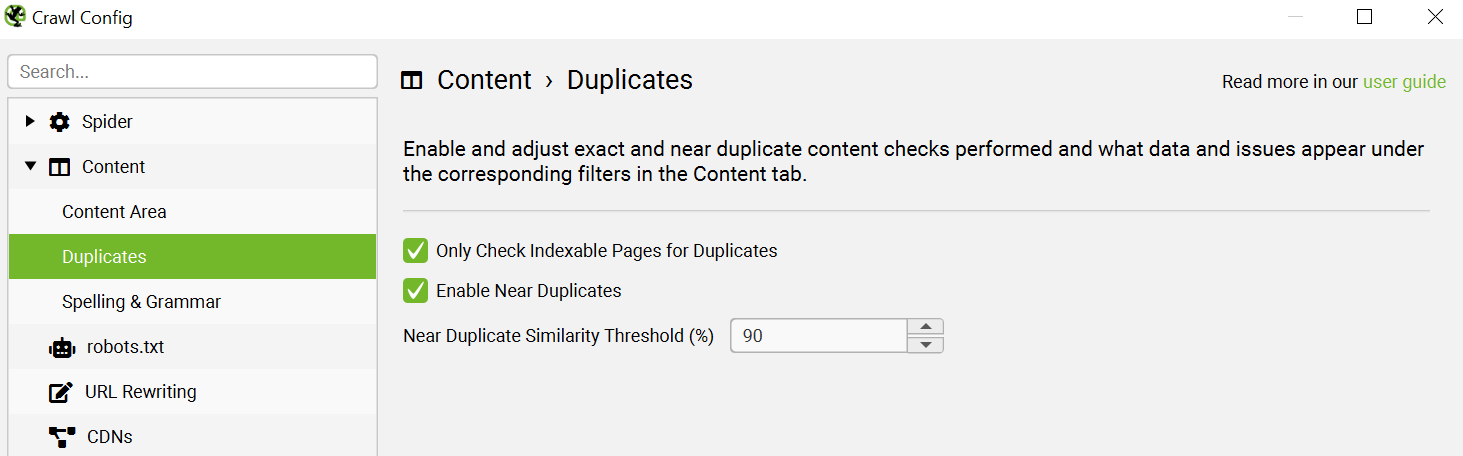
Screaming Frog (wewn. duplikacja treści)
Crawl domeny bądź poszczególnych jej sekcji/katalogów to pierwszy, podstawowy krok do gruntownej weryfikacji problemu duplicate content. Analiza wyników crawlowania pozwala na identyfikację powielonych adresów URL, statusu ich indeksacji oraz wdrożonych tagów takich jak np. canonical. Przydatne może okazać się skorzystanie z dedykowanego modułu narzędzia Duplicates do wykrywania duplikatów – do znalezienia w sekcji Content.
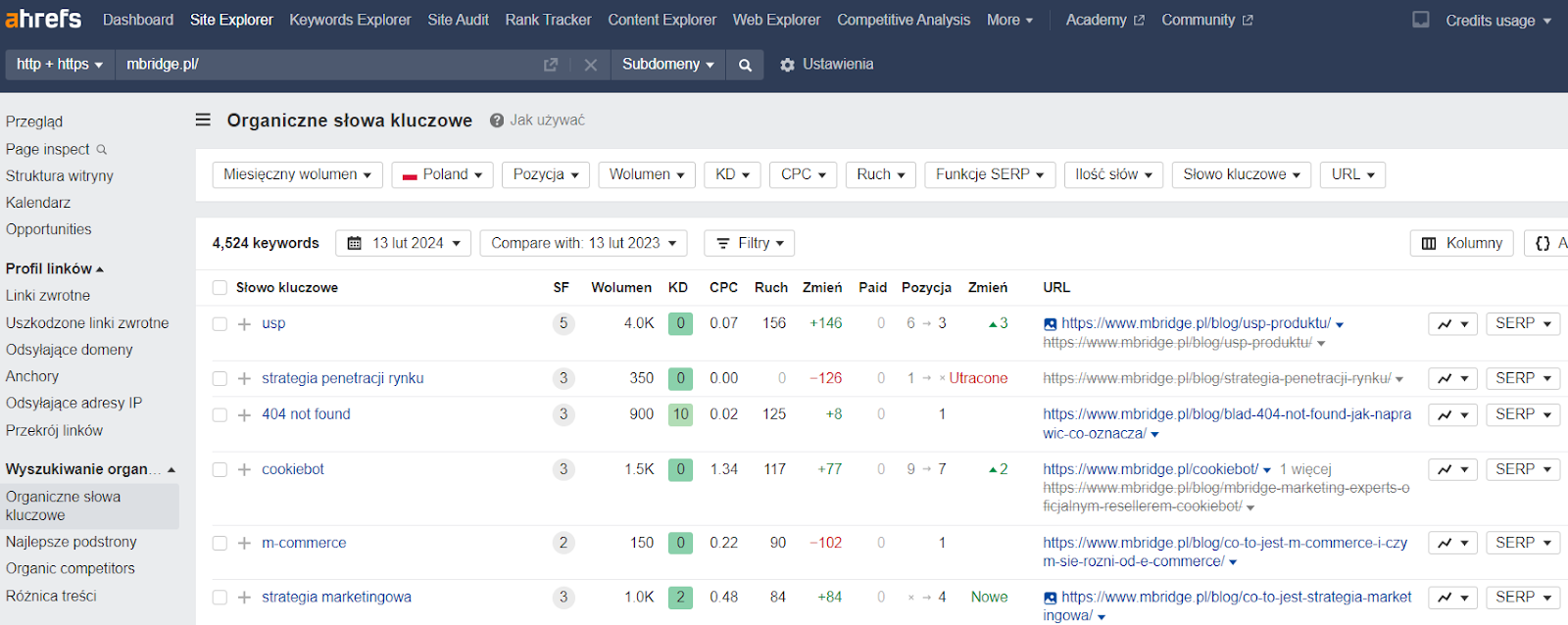
Google Search Console + Ahrefs / Senuto (wewn. duplikacja treści)
Problem wewnętrznej duplikacji treści często wiąże się z kanibalizacją podstron na tę samą frazę kluczową. W związku z tym, w rozpoznaniu duplikatów pomaga gruntowna analiza widoczności organicznej. Do jej przeprowadzania warto wykorzystać narzędzia zewnętrzne takie jak Ahrefs bądź Senuto, a także podpięte pod domenę Google Search Console. Jeśli na daną frazę w obrębie domeny wyświetla się więcej niż jedna podstrona, prawdopodobnie mamy do czynienia z duplikatami.
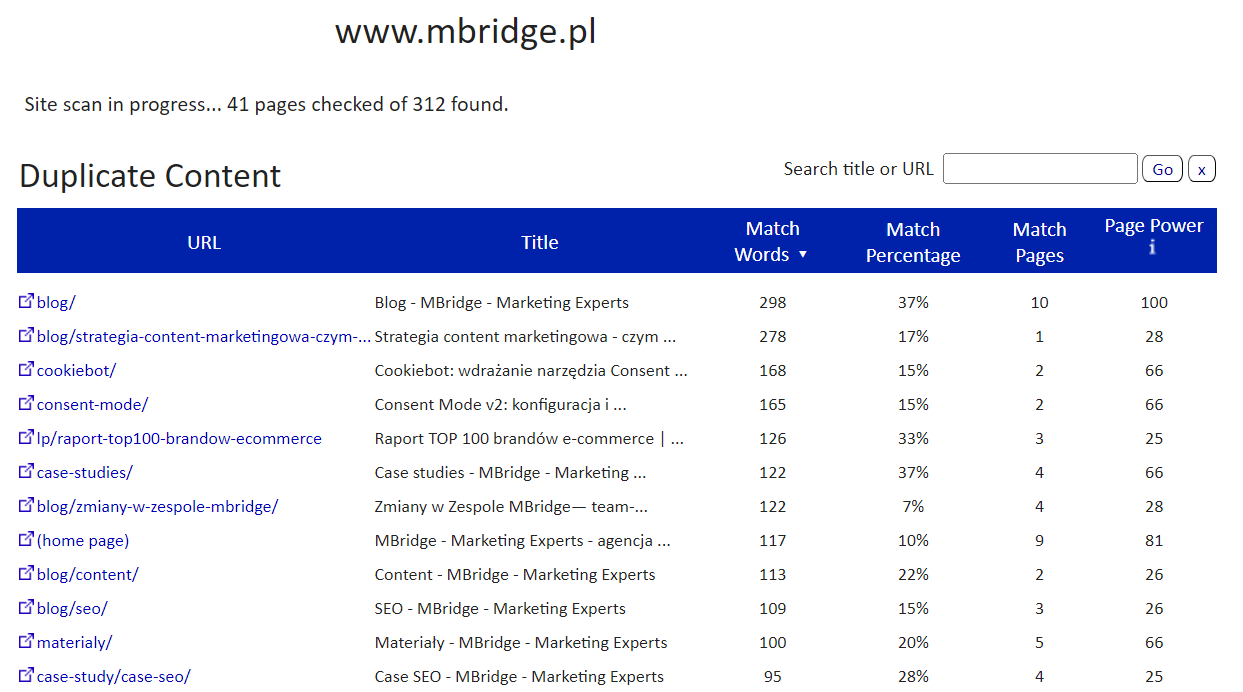
Siteliner (wewn. duplikacja treści)
Kolejne przydatne narzędzie, dostępne online w bezpłatnej wersji, które stoi na straży unikalności zawartości podstron. Na podstawie wpisanego adresu URL uzyskujemy listę podstron wykazujących największy stopień zbieżności treści, ustalanej pod kątem udziału identycznych wyrazów.
Duplikacja treści – co zrobić? Najlepsze praktyki
Jak poradzić sobie z duplikacją treści na stronie? Przede wszystkim: jak najszybciej.
A przy tym adekwatnie do występującego problemu.
W walce z duplicate content zaleca się stosować rozwiązania dopasowane do typu powielonych zasobów. Pamiętajmy przy tym, że podejmując działania mające na celu redukcję zduplikowanych treści na stronie, kierujmy się przede wszystkim wagą problemu determinującą priorytetyzację działań. Algorytm Google zwraca uwagę na większe “porcje” tekstu – pojedyncze zdania nie powinny zaszkodzić witrynie. Zatem zamiast skupiać się na wyrywkowej analizie każdego ze zdań, warto sprawdzać pełne opisy bądź akapity tekstów, a także całe podstrony pod kątem występowania duplikatów.
Duplikaty podstron w domenie
Według wskazówek dla webmasterów od Google problem duplikatów stron można rozwiązać na kilka sposobów. Przydatne okaże się przede wszystkim zaplanowanie, a następnie poprawne wdrożenie odpowiednich konfiguracji technicznych z zakresu: przekierowań 301, tagów: canonical, noindex bądź hreflang.
Jak wybrać właściwe rozwiązanie?
- Przekierowania 301 – wdrożenie stałego przekierowania sprawdzi się szczególnie dla powielonych podstron, które odnotowują już istotne wyniki organiczne. Dzięki takiemu rozwiązaniu zabezpieczymy dotychczas wypracowane efekty SEO, wskazując botom i użytkownikom właściwy, działający adres URL.
- Usunięcie podstron – to działanie należy wykonywać ze szczególną rozwagą. O ile bezpowrotne skasowanie zapomnianych “roboczych wersji” podstron prawdopodobnie nie będzie wiązać się z poważniejszymi konsekwencjami, o tyle pozbycie się podstron, które zdążyły zacząć generować ruch organiczny, zwiększa ryzyko spadków na wynikach domeny (bądź np. utratą cennych zewnętrznych linków odsyłających). W takiej sytuacji zdecydowanie lepszym rozwiązaniem w walce z duplicate content jest wdrożenie dopasowanych przekierowań 301.
- Tag “canonical” – jeżeli usunięcie powielonej podstrony nie wchodzi w grę można wspomóc się tagiem “canonical”. Jest to jasna podpowiedź dla botów Google’a, wskazująca kanoniczny (właściwy) adres URL. Poprzez użycie tagu zgłaszamy, że to właśnie ta wskazana podstrona powinna być brana pod uwagę w ustalaniu pozycji rankingowej w wyszukiwarce.
- Tag “noindex” – ten tag sygnalizuje potrzebę nieindeksowania wskazanego adresu URL w wyszukiwarce. Mówiąc prościej: gdy nie chcemy, by dana podstrona wyświetlała się w organicznych wynikach wyszukiwania. Tag znajduje zastosowanie w przypadku podstron, które występują w domenie z uwagi na inne cele: marketingowe bądź biznesowe, lecz z punktu widzenia SEO przysparzają dodatkowych utrudnień związanych z duplikacją treści.
- Atrybut “hreflang” – element kodu HTML wykorzystywany w przypadku obsługiwania kilku wersji językowych jednej podstrony. Połączenie ich tym atrybutem poprawi “zrozumienie” powiązania robotom skanującym zawartość witryny.
- Edycja pliku robots.txt – w przypadku niepożądanych duplikatów występujących w obrębie całych katalogów serwisu można rozważyć zablokowanie dostępu do nich botom indeksującym w pliku robots.txt.
Duplikaty treści na różnych podstronach domeny
Powielanie zasobów w obrębie więcej niż 1 podstrony będzie wymagać działań skupionych wokół reogranizacji istniejącej treści, czyli np. połączenia kilku artykułów w jeden, zrezygnowania ze zbędnych fragmentów bądź stworzenia unikalnych opisów.
Jak poradzić sobie z duplicate content na stronie?
- Usunięcie treści – z reguły na stronie pojawiają się miejsca, w których zduplikowana treść jest konsekwencją nieuwagi bądź automatyzacji. Trafnym przykładem takiej sytuacji jest zbędny tekst SEO na drugiej i kolejnych stronach paginacji np. na podstronie kategorii.
- Połączenie podstron – konsolidacja kilku podstron o mocno zbliżonej lub identycznej zawartości w jedną powinna zwalczyć problem duplikacji treści, a także kanibalizacji podstron, które możliwe, iż dotychczas budowały widoczność organiczną na te same frazy kluczowe. Co więcej pozwoli użytkownikom na dotarcie do kompletnego zbioru informacji umieszczonego pod jednym adresem URL, zawierającego wyczerpujące odpowiedzi na ich wszystkie pytania w ramach danego zagadnienia.
- Przeredagowanie treści – czasem okazuje się, że wystarczy zmodyfikować zawartość podstron-duplikatów do takiego stopnia, który wpłynie na zwiększenie ich unikalności. Warto zwrócić tutaj uwagę zarówno na treść (w tym strukturę nagłówków), jak również na metadane oraz wykorzystane zdjęcia i materiały video.
- Unikanie schematów – istotne zwłaszcza w przypadku form treści, które występują na wielu podstronach np. opisy produktowe. Opracowanie jednego generycznego modelu tekstu i dostosowywanie jedynie pojedynczych parametrów technicznych produktu, bywa niewystarczające.
Podczas zarządzania problemem duplicate content nie zapomnij o meta title i meta description. Zadbanie o ich unikalność dla każdej podstrony w serwisie pozwoli na dokładniejszą interpretację zawartości podstrony przez boty skanujące oraz użytkowników, a tym samym pozwoli na poprawę widoczności strony w Google i konwersyjności podstrony w wyszukiwarce.
Zewnętrzne duplikaty treści
Ograniczone pole manewru w zarządzaniu duplikatami zewnętrznymi nie oznacza braku możliwości do działania. Zawsze opłaca się stawiać na pierwszym miejscu dbałość o unikalny content na swojej stronie, a w przypadku podejrzenia bycia ofiarą plagiatu (który może zaszkodzić także Twojej witrynie) warto bez zawahania podjąć próby kontaktu z właścicielem zewnętrznego serwisu. Zgłoszenie wniosku o usunięcie tekstu bądź prośby o wskazanie autora i linku do źródła zapewni ochronę nie tylko efektom pozycjonowania domeny, lecz również wizerunkowi marki.
Czasem zdarzy się, że najbezpieczniejszym rozwiązaniem będzie uniemożliwienie indeksacji podstron, które można uznać za duplicate content, gdyż występują na dużej ilości serwisów. Dotyczy to elementów witryny, które nie budują widoczności organicznej w wyszukiwarce, a jednak powinny wyświetlać się w serwisie np. ze względów prawnych – takie jak polityka prywatności bądź polityka zarządzania plikami cookies.
Jeśli w ramach jednego podmiotu obsługiwanych jest kilka domen np. firmowych/ofertowych, przydatna może okazać się także generalna weryfikacja w obrębie wszystkich witryn, gdzie nieumyślnie mogły zostać powielone np. opisy świadczonych usług. Podobna sytuacja występuje, gdy udostępniamy wizytówkę firmy w katalogach branżowych, portalach z ofertami pracy lub agregatorach sklepów/usługodawców.
Duplicate content nie oszczędza nawet domen będących w procesie migracji. Nigdy nie zaszkodzi zatem upewnić się, czy nowa wersja strony, dopóki nie będzie gotowa, nie jest indeksowana przez wyszukiwarkę – to także bywa przyczyną tworzenia zewnętrznych duplikatów. Z kolei po zakończonej migracji obowiązkowo należy zweryfikować poprawność mapowania adresów URL, co pozwoli uniknąć powielenia treści na wciąż działających, starych oraz już działających, nowych podstronach. Ponadto w ramach tego działania warto ocenić poprawność pliku robots.txt oraz sprawdzić tagi noindex tak, by ograniczyć dostęp botom indeksującym do miejsc, po których nie powinny wędrować.
A co, jeżeli duplikacja treści to jedyne rozwiązanie?
Czasem, pomimo starań i świadomości ponoszonego ryzyka, nie da się obejść umieszczenia na stronie fragmentu tekstu, który pojawia się w innych miejscach w sieci bądź na innej podstronie w obrębie domeny. Spokojnie, niekoniecznie musi to od razu oznaczać narażanie się na “krytyczny osąd” przez algorytm Google.
W przypadku wewnętrznych duplikatów można rozpatrzyć wdrożenie omawianego wcześniej tagu canonical, wskazującego Googlebotowi kanoniczną wersję podstrony – tę, która powinna zostać zaindeksowana i wyświetlona w wyszukiwarce. Z kolei przy pozyskiwaniu fragmentów treści z zewnętrznych domen nie zapomnij o wyraźnym zaznaczeniu autora tekstu oraz umieszczeniu linku do oryginalnego źródła.
Podsumowanie
Jak się okazuje, problem duplicate content w SEO wcale nie musi być faktycznym problemem (co potwierdzają sami twórcy wyszukiwarki). Wystarczy mieć świadomość, jakie formy duplikatów spotykają się z przychylną oceną przez algorytm Google, a jakie narażają naszą witrynę na niepożądane ryzyko pogorszenia wyników.
Warto pamiętać, że regularna weryfikacja i aktualizacja zasobów, jakimi dysponuje witryna, pozwala na skuteczne zarządzanie pojawiającymi się duplikatami treści. A wdrożenie wobec nich odpowiednio dopasowanych kroków zapewni domenie bezpieczny start w walce o najwyższe pozycje w wynikach wyszukiwania.
Masz problem z SEO? Sprawdź naszą ofertę!









